Funktionales Deep Learning in Haskell - Teaser
Bei der Active Group entwickeln wir für Siemens eine App, die mithilfe Neuronaler Netze Anomalien in Produktionsprozessen erkennen soll. Während Python unbestritten die alles dominierende Sprache in Sachen Deep Learning ist, haben wir natürlich nach einer funktionaleren Lösung gesucht und sind dabei in Conal Elliots GHC-Plugin ConCat fündig geworden. Im ersten Teil dieser Reihe schauen wir uns an, warum ConCat eine attraktive Alternative zu gängigen Bibliotheken wie TensorFlow oder PyTorch ist, und geben einen ersten groben Einblick in die Funktionsweise von Deep Learning mit ConCat.1
Was macht eigentlich so eine Deep Learning-Bibliothek?
Fürs Verständnis dieses Blogposts genügt es, sich ein Neuronales Netz als eine Funktion mit vielen Parametern vorzustellen. Während des sogenannten Trainings sollen die Parameter so eingestellt werden, dass das Netz auf einem gegebenen Datensatz möglichst „gute“ Ausgaben produziert. Wie gut eine Ausgabe ist, wird dabei anhand einer Fehlerfunktion beurteilt, die in den meisten Fällen die Ausgabe des Netzes mit einer vorgegebenen, gewünschten Ausgabe vergleicht und daraus eine Zahl berechnet. Wir haben es hier also mit einem Optimierungsproblem zu tun, bei dem die eben erwähnte Zahl minimiert werden soll.
Für Neuronale Netze funktioniert das erfahrungsgemäß am besten mit dem Gradientenverfahren. Dabei wird zunächst eine zu optimierende Funktion nach ihren Parametern abgeleitet. Die Ableitung zeigt in Richtung des steilsten Anstiegs. Werden die Parameter nun entlang oder entgegen ihrer Ableitung angepasst, stehen die Chancen gut, dass die Funktion mit den angepassten Parametern höhere bzw. niedrigere Werte produziert als vorher (sofern man dabei keinen zu großen Schritt gemacht hat).
Es wundert daher nicht, dass die Kernkompetenz von Deep Learning-Bibliotheken das automatische Berechnen von Ableitungen ist. Als Komposition vieler Teilfunktionen ist die Ableitung eines Neuronalen Netzes nach der Kettenregel eine Komposition vieler Teilableitungen. Da Funktionskomposition assoziativ ist, steht uns frei, in welcher Reihenfolge wir die Komponenten auswerten. Wie sich herausstellt, ist dabei der Rechenaufwand bei rechtsassoziativer Auswertung (vorwärts) abhängig von der Eingangsdimension – das ist in diesem Fall die Anzahl der Parameter – und für den linksassoziativen Fall (rückwärts) abhängig von der Ausgangsdimension – in diesem Fall 1, da die Fehlerfunktion ja eine Zahl ausgibt. Es wundert daher auch nicht, dass Deep Learning-Bibliotheken linksassoziativ arbeiten.
Wie folgendes Beispiel zeigt
(g o f)'(x) = g'(f(x)) o f'(x)
gibt es dabei ein ziemlich kniffliges Problem: Um g'(f(x)) auszuwerten, müssen wir
f(x) kennen. Wir brauchen daher ein Programm, welches das gesamte Neuronale Netz
einmal vorwärts auswertet, sich dabei alle Zwischenergebnisse und die Operationen,
die diese erzeugt haben, merkt und diese Informationen in der rückwärtsläufigen
Berechnung der Ableitung wieder abgreift. All diese Informationen werden in einem
sogenannten Wengert- oder Gradient-Tape gespeichert und die Generierung und
Verwaltung eines solchen Tapes ist das, was Deep Learning-Bibliotheken eigentlich so
machen.
Deep Learning mit TensorFlow
In TensorFlow kann man sich dieses Tape (etwas lose aufgefasst) sogar anschauen. Das sieht z. B. so aus:
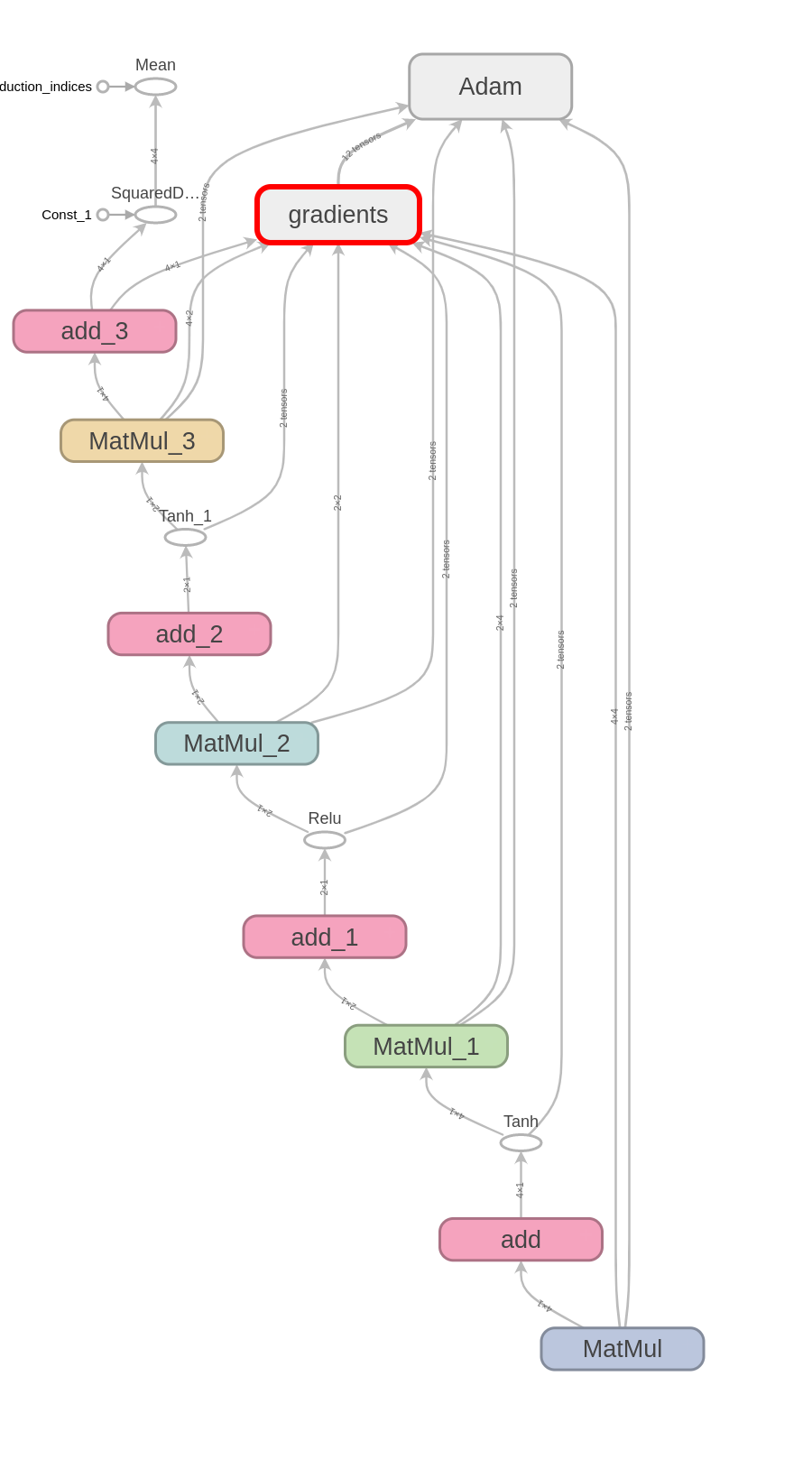
Dieser Tape- oder Graphen-basierte Ansatz bringt leider mit sich, dass alles, was wir
in TensorFlow machen, im Hintergrund in einen Teil einer ziemlich komplizierten
Maschinerie übersetzt werden muss. Interessierte LeserInnen mögen versuchen, zu
verstehen, was TensorFlow z. B aus
einem harmlosen + so alles macht .
Beispiel: Simples Neuronales Netz in TensorFlow
Folgendermaßen könnte man in TensorFlow ein simples Neuronales Netz implementieren, das aus vier Schichten (im Wesentlichen Matrixmultiplikationen) besteht, jeweils gefolgt von einer Aktivierungsfunktion.
class SimpleNeuralNetwork:
def __init__(self, dim):
self.dims = [dim, dim, dim // 2, dim // 2, dim]
self.weights = []
self.biases = []
for i in range(4):
self.weights.append(
tf.Variable(tf.random.normal(shape=(self.dims[i+1],self.dims[i])))
)
self.biases.append(
tf.Variable(tf.random.normal(shape=(self.dims[i+1],1)))
)
def __call__(self, x):
inputs = tf.convert_to_tensor([x], dtype=tf.float32)
out = tf.matmul(self.weights[0],
inputs, transpose_b=True) + self.biases[0]
out = tf.tanh(out)
out = tf.matmul(self.weights[1], out) + self.biases[1]
out = tf.nn.relu(out)
out = tf.matmul(self.weights[2], out) + self.biases[2]
out = tf.tanh(out)
return tf.matmul(self.weights[3], out) + self.biases[3]
Ohne zu sehr in Details zu gehen, lassen sich hieran schon einige Probleme erkennen:
- Der Code ist sehr unübersichtlich und kompliziert.
- Große Teile des Codes haben gar nichts mit dem eigentlichen Netz zu tun, sondern
mit dem TensorFlow-Graphen. Z. B. die Konvertierung der Parameter (
tf.Variable) und des Inputs (tf.convert_to_tensor) sowie indirekt alle Funktionen, die aus TensorFlow kommen (s. obige Bemerkung zu+). - Der Code ist sehr spezialisiert auf TensorFlow-interne Typen (
dtype=tf.float32und eben erwähnte Konvertierungen). Generalisierung und Abstraktion ist in diesem Kontext kaum noch möglich. - Die einzelnen Teile des Graphen lassen sich überhaupt nicht mehr separat testen; um zu überprüfen, ob das Netz korrekte Werte ausgibt, muss man den ganzen Graphen laufen lassen.
- Manche Teile von Python sind kompatibel mit dem TensorFlow-Graphen, andere nicht.
Außerdem ist das Ganze ist sehr anfällig für Fehler, die erst zur Laufzeit (teils kryptische) Meldungen produzieren. Wenn man z. B. in obiger Definition der call-Methode…
def __call__(self, xs):
...
out = tf.matmul(self.weights[0],
inputs, transpose_b=True) + self.biases[0]
...
den wichtigen Hinweis transpose_b=True weglässt, erhält man beim Ausführen des
Netzes folgende Fehlermeldung:
>>> import simple_neural_network as nn
>>> simple_nn = nn.SimpleNerualNetwork(4)
>>> simple_nn([1,2,3,4])
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/nix/store/2l3cr4ksxsz96ixz1dl2gdxg50byl45l-python3-3.10.4-env/lib/python3.10/site-packages/tensorflow/python/util/traceback_utils.py", line 153, in error_handler
raise e.with_traceback(filtered_tb) from None
File "/nix/store/2l3cr4ksxsz96ixz1dl2gdxg50byl45l-python3-3.10.4-env/lib/python3.10/site-packages/tensorflow/python/framework/func_graph.py", line 1147, in autograph_handler
raise e.ag_error_metadata.to_exception(e)
ValueError: in user code:
File ".../simple_neural_network.py", line 19, in __call__ *
out = tf.matmul(self.weights[0], tf.convert_to_tensor([x], dtype=tf.float32)) + self.biases[0]
ValueError: Dimensions must be equal, but are 4 and 1 for '{node MatMul} = MatMul[T=DT_FLOAT, transpose_a=false, transpose_b=false](MatMul/ReadVariableOp, Const)' with input shapes: [4,4], [1,4].
Das ist in diesem Fall noch einfach zu beheben; derartige Fehler können aber ziemlich schnell in tagelange Fehlersuche ausarten.
Deep Learning mit ConCat
Grob gesagt abstrahiert ConCat mittels Kategorientheorie über Haskells Funktionspfeil ->,
um ihn auf verschiedene Weisen zu interpretieren. So können wir eine Funktion z. B.
in ihre rückwärtsläufige Ableitung uminterpretieren. Das Schöne dabei ist, dass das
Ganze in GHCs Kompilierprozess passiert – sowohl die Funktion als auch ihre
Ableitung (nachdem sie uminterpretiert wurde) sind dabei ganz normale Haskell-Funktionen.
Ein Gradient-Tape müssen wir weder generieren noch verwalten.
Mit ConCat könnte man daher das obige Neuronale Netz so implementieren:
type SimpleNeuralNetworkPars (f :: Nat -> * -> *) n m =
( (f m --+ f n)
:*: (f m --+ f m)
:*: (f n --+ f m)
:*: (f n --+ f n)
)
simpleNeuralNetwork ::
(KnownNat n, KnownNat m, Additive numType, Floating numType, Ord numType) =>
SimpleNeuralNetworkPars f n m numType -> f n numType -> f n numType
simpleNeuralNetwork = affine @. affTanh @. affRelu @. affTanh
Diesmal lassen sich ohne zu sehr in Details zu gehen schon einige Vorteile verdeutlichen:
- Der Code ist auf die wesentlichen Konzepte reduziert.
- Das Neuronale Netz ist eine pure, ganz normale Haskell-Funktion, die das, und nur das macht, was ein Neuronales Netz so macht.
- Die API für das Neuronale Netz ist demnach einfach Haskell. Dadurch ist eine reibungslose Integration mit anderen Teilen eines Programms möglich.
- Die Typen sind generisch gehalten.2
- Das Neuronale Netz lässt sich leicht testen.
Außerdem werden die meisten Fehler schon beim Kompilieren gefunden. Insbesondere weist GHC durch Verwendung von Datentypen, die Informationen über ihre Dimension enthalten, darauf hin, wenn irgendwo Dimensionen nicht zusammenpassen.
Jetzt wissen wir schon mal, warum wir für Deep Learning vielleicht lieber ConCat benutzen. Aber wie macht man denn jetzt Deep Learning mit ConCat eigentlich? Das schauen wir uns in einem späteren Blogpost an.
Fußnoten
-
Es sei darauf hingewiesen, dass ConCat keine Deep Learning-Bibliothek, sondern Deep Learning nur eins von vielen Anwendungsbeispielen für ConCat ist; eine ausgewachsene Deep Learning-Bibliothek gibt es hierfür noch nicht. Wir arbeiten aber daran. ↩
-
(--+)ist ein Typ-Alias, das lediglich ein paar Operatoren aus GHC.Generics benutzt, wo auch(:*:)herkommt; der Kombinator für die Schichten eines Netzes ist folgendermaßen definiert:(@.) :: (q s -> b -> c) -> (p s -> a -> b) -> ((q :*: p) s -> a -> c) (g @. f) (q :*: p) = g q . f p
