Funktionale Programmierung ist längst den Kinderschuhen entwachsen.
Inzwischen setzen auch Firmen wie
z.B. Twitter
oder Microsoft
auf funktionale Programmierung, um damit sichere, korrekte und performante
Software in kurzer Zeit zu entwickeln.
Heute zeigen wir anhand eines Beispiels aus der Praxis, welche
Produkte wir als Firma mit funktionaler Programmierung realisieren.
Konkret geht es um das Produkt Checkpad MED,
eine digitale und mobile Krankenakte für Krankenhausärzte
(Film,
Homepage).
Checkpad MED
wird in Kooperation mit Lohmann & Birkner
unter technischer Federführung der factis research
GmbH zu einem großen Teil
in funktionalen Programmiersprachen entwickelt, im restlichen
Teil setzen wir zumindest auf funktionale Paradigmen und Techniken.
In diesem Artikel
soll es erstmal weniger um technische Details gehen sondern
vielmehr um einen Überblick über das System und seine Architektur.
Denn auch auf der Architekurebene kann man Prinzipien der funktionalen
Programmierung anwenden und damit Vorteile bzgl. guter Testbarkeit und
Nachvollziehbarkeit genießen.
Checkpad MED, eine mobile Krankenakte
Checkpad MED ist eine digitale, mobile Krankenakte, die Ärzten im
Krankenhaus jederzeit und überall Zugriff auf die relevanten
Patientendaten, wie etwa die Krankengeschichte, Arztbriefe, Laborwerte,
Röntgenbilder, OP-Berichte und vieles mehr erlaubt. Darüberhinaus bietet
die Anwendung durch ein Aufgaben- und Notizsystem die Möglichkeit,
Arbeitsabläufe im Klinikalltag besser zu organisieren.
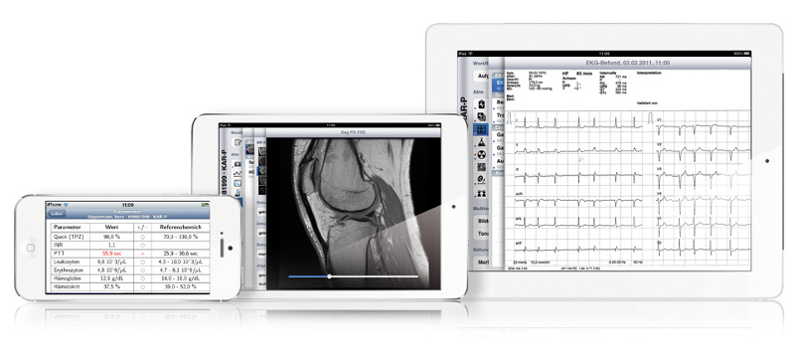
Der Client für Checkpad MED ist als iOS-App realisiert, die auf iPad,
iPhone und iPod läuft. Die folgenden Screenshots zeigen verschiedene
Ansicht des Clients.
</img>
Systemarchitektur
Der weitaus größere Teil des Checkpad-Systems ist allerdings
serverseitig realisiert, wobei auf dem Server mit
Haskell und Scala
fast ausschließlich funktionale Programmiersprachen zum Einsatz kommen.
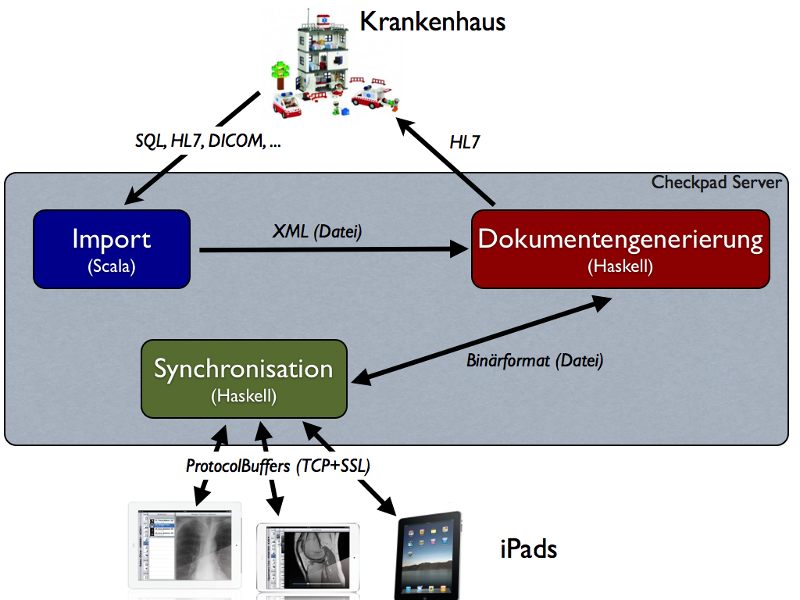
Folgendes Diagramm zeigt die Gesamtarchitekur des Systems:
</img>
Das System ist im wesentlichen eine Pipeline, die Daten aus dem Krankenhaus
importiert, verarbeitet und auf die mobilen Clients überträgt. Zusätzlich
gibt es noch einen Rückkanal, auf dem mit den mobilen Clients erfasste
Daten in die Krankenhaus-IT zurückfließen.
Die Pipeline basiert auf dem Push-Prinzip, d.h. neue Daten werden von einer
Komponente in die nächste geschoben. Im Gegensatz zu einem Poll-System, in
dem eine Komponente die Daten bei der vorhergehenden Komponente abfragt, ergibt
sich damit für neue Daten ein schnelleres Durchlaufen der Pipeline bei geringerer Last.
Für die Nutzer des Systems (d.h. die Ärzte) liegt der Vorteil dieses
Ansatzes auf der Hand, denn sie sehen nun neue Daten direkt und schnell
auf ihrem iPad oder iPhone, ohne ständig die Ansicht manuell aktualisieren
zu müssen.
Betrachten wir nun die einzelnen Komponenten etwas detaillierter.
- Krankenhaus
- Ein Krankenhaus kann die erforderlichen Daten dem Checkpad-Server über
eine Vielzahl von Schnittstellen zur Verfügung stellen. Exemplarisch seien
hier nur
DICOM
zur Übertragung von Radiologiebildern, sowie
HL7 zur Übertragung von Patienten- und
Befunddaten genannt. Einige Krankenhäuser setzen aber auch proprietäre
Schnittstellen wie z.B. den Direktzugriff auf SQL-Datenbanken ein.
- Import
- Die Import-Komponente stellt Adapter für die verschiedenen
Krankhausschnittstellen zur Verfügung und bringt die Daten in eine
standardisierte Form. Die standardisierten Daten werden der
Dokumentengenerierung, also der nächsten Komponente der Pipeline,
in einem XML-Format zur Verfügung gestellt.
Da für viele Schnittstellen bereits Java-APIs zur
Verfügung stehen, haben wir die Import-Komponente in der
funktional-objektorientierten Sprache Scala
implementiert. Durch den Einsatz von Scala können wir alle Java-APIs
problemlos und einfach wiederverwenden.
- Dokumentengenerierung
- Die Dokumentengenerierung interpretiert und aggregiert die importieren
Daten. Zusätzlich werden die Daten für die mobilen Clients entsprechend
aufbereitet und als Dokumente in einem Binärformat serialisiert.
Die Dokumentengenerierung funktioniert ähnlich wie ein
kontinuierlich laufendes Buildsystem: bei Änderung der Eingangsdaten
(Importdaten) werden die Dokumente, die von den geänderten Eingangsdaten
abhängen, automatisch neu generiert.
Die Dokumentengenerierung ist
komplett in Haskell geschrieben.
- Synchronisation
- Die Synchronisations-Komponente ist im wesentlichen ein TCP-Server, der
über eine sichere Verbindung die erzeugten Dokumente auf die mobilen Geräte
synchronisiert. Die mobilen Geräte sind komplett offline-fähig. Daher
verwaltet die Synchronisations-Komponente für jeden mobilen Client dessen
aktuellen Synchronisationsstand und pusht neue Dokumente auf den Client,
sobald dieser online ist. Auch der Synchronisations-Server ist in
Haskell geschrieben
- Mobile Clients
- Die Client-App ist ein offline-fähiger Browser für ein proprietäres
Dokumentenformat. Sie empfängt Dokumente als Protocol
Buffers, speichert diese
verschlüsselt im persistenten Speicher und rendert die Dokumente
mittels nativer iOS-UI-Komponenten. Die Client-App ist in Objective-C
realisiert.
Funktionale Prinzipien
Wir haben uns bei der Architektur des Systems von drei wesentlichen
Prinzipien leiten lassen:
- Push statt Poll.
- Alle Komponenten arbeiten idempotent, d.h. sie erzeugen bei gleicher
Eingabe dieselbe Ausgabe.
- Die Historie der Ein- und Ausgabedaten wird, wo immer möglich, erhalten,
d.h. Daten werden nicht überschrieben sondern es wird immer eine neue
Version angelegt.
Das erste dieser Prinzipien ist sicher kein funktionales Prinzip.
Aufmerksame Leser unseres Blogs erkennen in den anderen beiden Punkten
jedoch sicherlich ein typisches
Designmuster von funktionalen Programmen: Seiteneffekte vermeiden, alle
Abhängkeiten explizit machen!
Die Vorteile dieses Vorgehens sind klar:
- Alte Systemzustände und damit mögliche Fehlerkonstellationen können
leicht geprüft und getestet werden.
- Es ist jederzeit ersichtlich, was welcher Arzt wann auf seinem iPad oder
iPhone gesehen hat.
- Die Implementierung eines verteilten Systems wird durch Idempotenz enorm
erleichtert.
Auch im Objective-C Code der Client-App machen wir Gebrauch von
funktionalen Paradigmen und Techniken, obwohl Objective-C wahrlich keine
funktionale Sprache ist. In einem vorigen
Blogartikel
ist z.B. nachzulesen welche Vorteile es hat persistente
Datenstrukturen
in Objective-C zu verwenden.
Ausblick
Dieser Artikel hat Ihnen einen ersten Eindruck über ein großes, fast
komplett mit funktionalen Sprachen realisiertes System gegeben. (Das
System besteht aus fast 100.000 Zeilen Haskell Code, etwa 35.000 Zeilen
Scala Code und etwa 56.000 Zeilen Objective-C Code.)
In späteren Artikeln werden wir dann auf dieser Grundlage
auch technische Details und die Vorzüge der
funktionalen Programmierung beim Lösen spezifischer Probleme erklären.
Wir freuen uns über Rückfragen und Rückmeldungen jedweder Art!